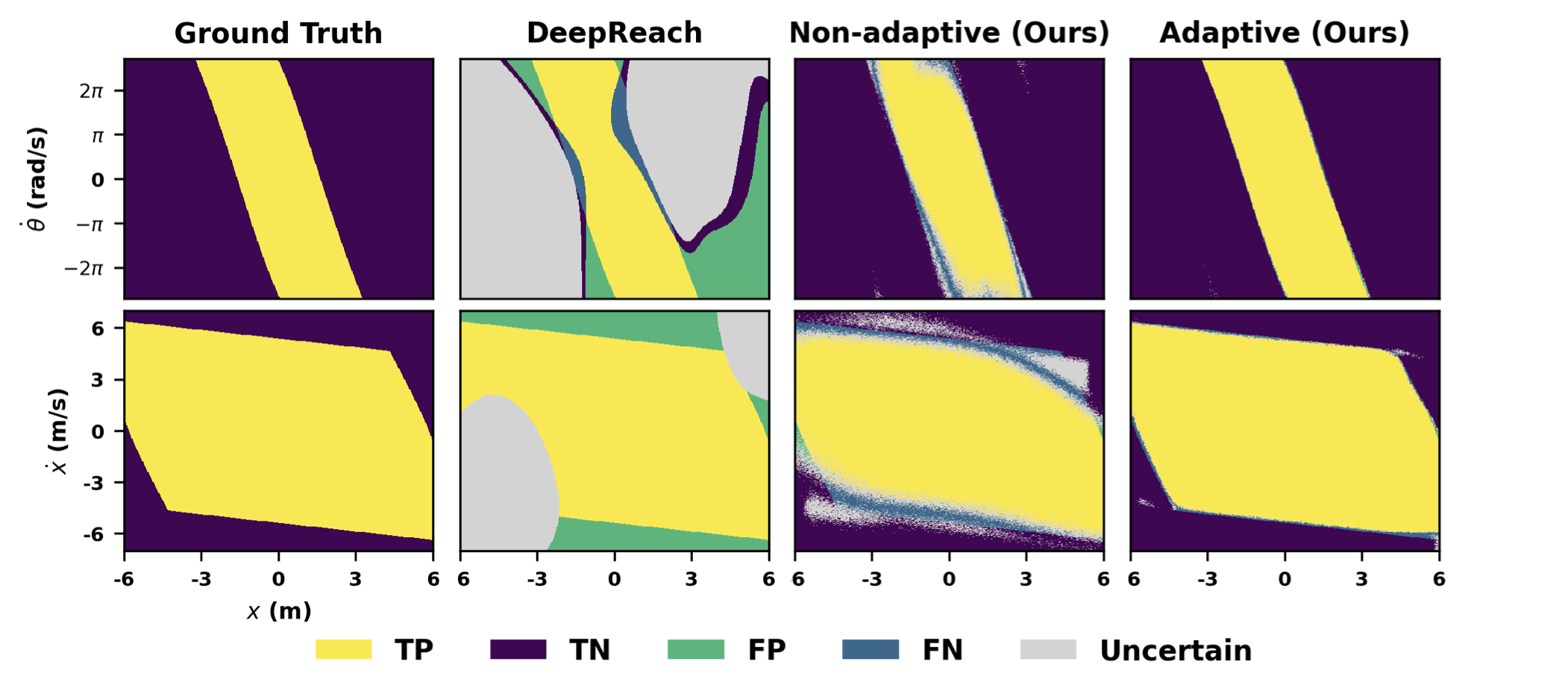
We evaluate on four dynamical systems of increasing dimensionality, from a 2D pendulum to a 13D spatial quadrotor.
Verification of robot controllers is important for ensuring safe and reliable robot operation. It can involve the characterization of a controller's Region of Attraction (RoA), i.e., the initial states that lead to a successful outcome. This is challenging, however, for black-box, learned controllers where analytical models are unavailable. In such scenarios, verification is conducted using only trajectory data, making data efficiency critical as each data point represents a costly physical experiment. To address this, this paper presents a framework that integrates three components: (1) a Conditional Flow Matching (CFM) model that learns the distribution of final states from initial conditions, capturing multi-modal outcome distributions that naturally express uncertainty near the boundary between success and failure regions; (2) a probabilistic classification mechanism that interprets the learned distribution via optimized decision thresholds to categorize states into the RoA, the failure region, or an uncertain region where the model cannot commit to an outcome; and (3) an adaptive sampling strategy that concentrates trajectory collection on the uncertain region to reduce it with fewer rollouts than uniform sampling. The resulting predictions are certified via conformal inference to provide finite-sample coverage guarantees. Experiments on benchmark systems ranging from a 2D pendulum to a 13D quadrotor demonstrate that the proposed framework achieves high verification accuracy with low uncertainty compared to existing methods, and that adaptive sampling further improves data efficiency over the non-adaptive variant.
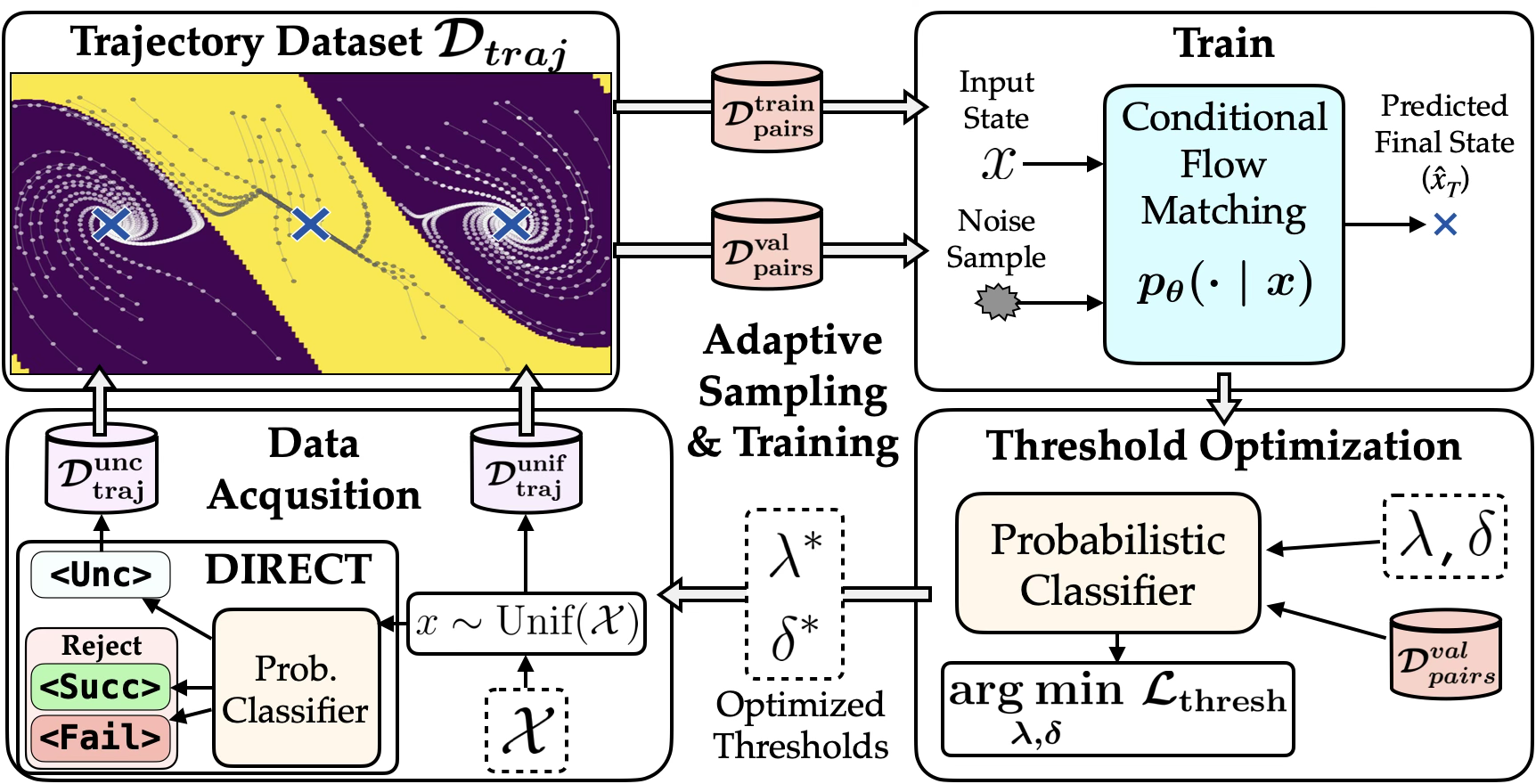
Our framework estimates the Region of Attraction (RoA) of a black-box controller through three integrated components. Each initial state is classified into one of three labels:
<Succ> – the state lies within the RoA and the controller succeeds<Fail> – the state lies outside the RoA and the controller fails<Unc> – the model cannot confidently commit to an outcomeThese labels are assigned through three integrated components:
<Succ> and <Fail> regions.<Succ>, <Fail>, or <Unc>, with thresholds optimized to balance accuracy and the size of the <Unc> region.<Unc> region guides data collection, concentrating costly trajectory rollouts on boundary states where the classifier cannot commit, progressively refining the RoA characterization.Finally, a conformal inference layer certifies all predictions with finite-sample coverage guarantees.
For each query state, the CFM model draws $K$ predicted final states via Monte Carlo sampling. Each sample is evaluated against both success criteria ($\gamma_s$) and failure criteria ($\gamma_f$) to produce three probability estimates:
A threshold-based decision rule then classifies each state: high $\hat{p}_s$ yields <Succ>, high $\hat{p}_f$ yields <Fail>, and states with high model error or where neither probability is decisive are labeled <Unc>.
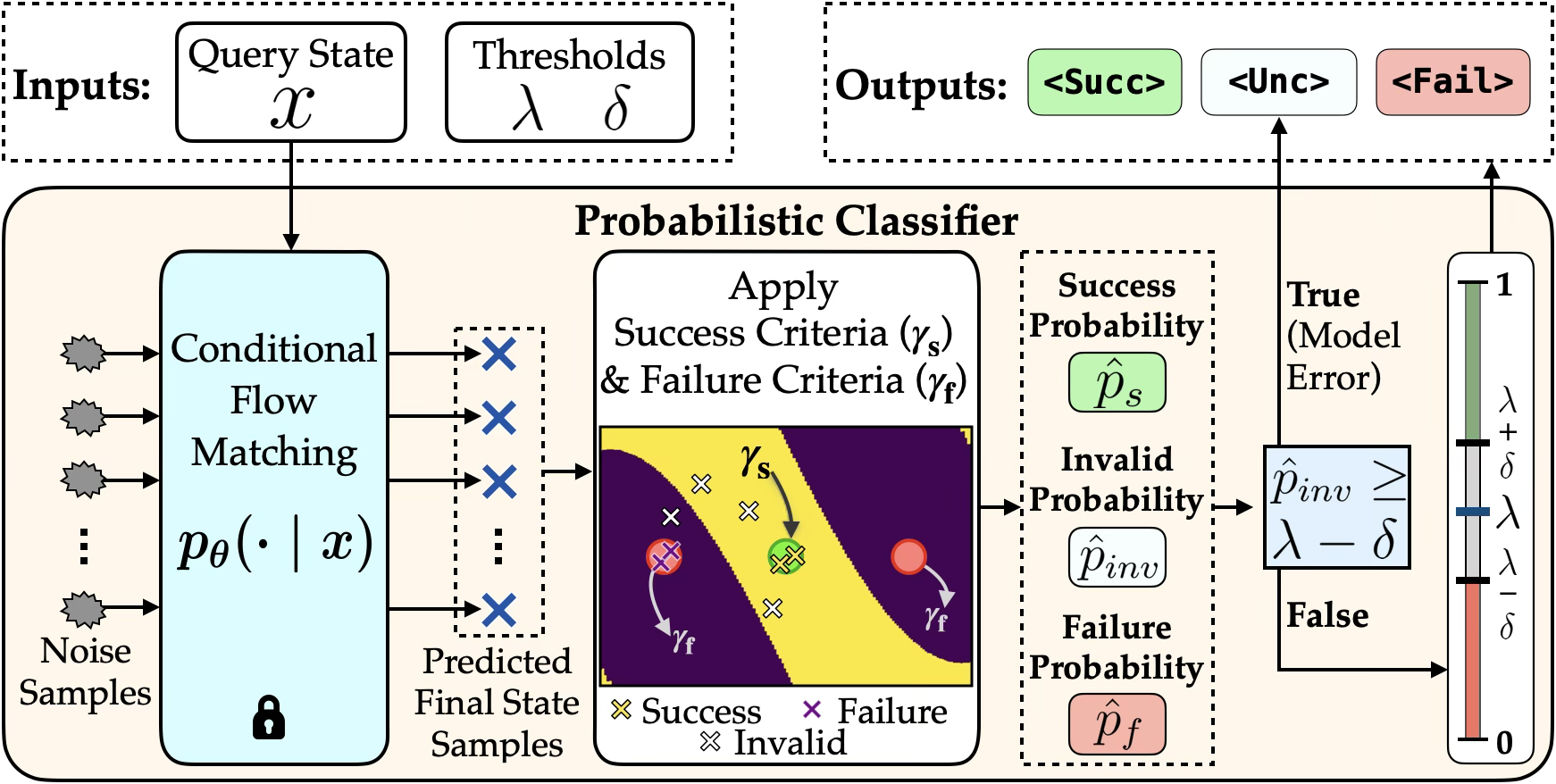
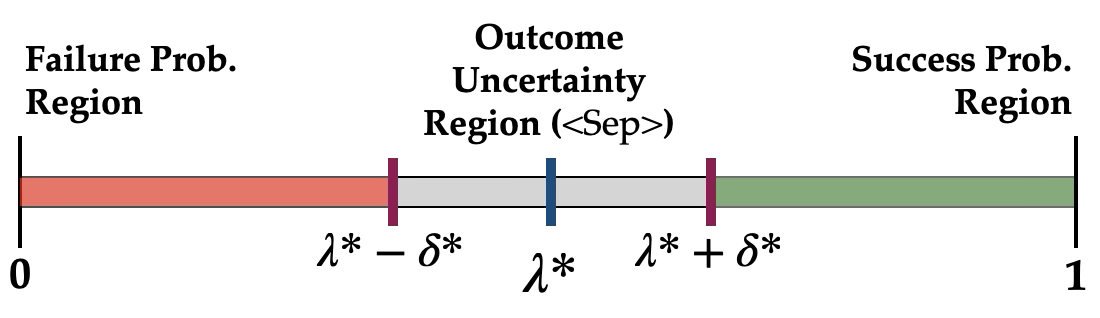
Given the three probability estimates $\hat{p}_s(x)$, $\hat{p}_f(x)$, and $\hat{p}_\text{inv}(x)$, a threshold-based decision rule maps each state to one of three labels. The rule is parameterized by a center $\lambda$ and a margin $\delta$, which define decision boundaries $\theta_s = \lambda + \delta$ and $\theta_f = 1 - (\lambda - \delta)$. Classification proceeds in three stages:
<Unc>—too many generated samples are invalid, indicating the model has not learned this region well.<Succ>; if $\hat{p}_f(x) \geq \theta_f$ it is classified as <Fail>.<Unc>.
The parameters $\lambda^*$ and $\delta^*$ are jointly optimized on a validation set to minimize a weighted combination of classification error (fraction of confident predictions that disagree with ground truth) and the size of the <Unc> region. This balances two competing goals: reducing misclassifications while keeping the uncertain region as small as possible.
Most of the state space is homogeneous—clearly within the <Succ> or <Fail> region. The critical boundary between them occupies a thin manifold that is underrepresented under uniform sampling. Our DIRECT acquisition algorithm identifies states classified as <Unc> and preferentially collects new trajectory data from this region. Over multiple iterations, the framework progressively refines the RoA boundary characterization, achieving approximately 1.5× data savings compared to uniform sampling.
A split conformal prediction layer certifies the framework's outputs with provable, finite-sample coverage guarantees. A held-out calibration set $\mathcal{D}_\text{cal}$ with ground-truth labels is used to compute nonconformity scores that measure how inconsistent the model's probability estimates are with each candidate label. States flagged as model error ($\hat{p}_\text{inv} \geq \lambda^* - \delta^*$) are filtered from the calibration set to avoid inflating the conformal quantile with modeling artifacts. For a user-specified confidence level $1-\alpha$, the conformal procedure produces prediction sets guaranteed to contain the true outcome with probability at least $1-\alpha$. Singleton prediction sets ({<Succ>} or {<Fail>}) indicate high-confidence classifications, while non-singleton sets containing <Unc> serve as certificates of abstention. Empirically, coverage exceeds 0.98 across all four benchmark systems at $\alpha = 0.1$, with nearly all predictions being confident singletons.
We evaluate on four dynamical systems of increasing dimensionality, from a 2D pendulum to a 13D spatial quadrotor.
Pendulum (2D)
State: $(\theta, \dot{\theta})$
LQR control
Cartpole (4D)
State: $(q, \theta, \dot{q}, \dot{\theta})$
LQR control
Planar Quadrotor (6D)
State: $(q_x, q_z, \phi, \dot{q}_x, \dot{q}_z, \dot{\phi})$
Learned RL policy
Spatial Quadrotor (13D)
State: $(q, q_\text{quat}, \dot{q}, \omega)$
LQR control
Baselines shown at full evaluation budget. Drag sliders to explore how our methods (highlighted) perform with fewer trajectories.